Recent breakthroughs in text-guided image generation have led to remarkable progress in the
field of 3D synthesis from text. By optimizing neural radiance fields (NeRF) directly from text,
recent methods are able to produce remarkable results.
Yet, these methods are limited in their control of each object's placement or appearance, as
they represent the scene as a whole.
This can be a major issue in scenarios that require refining or manipulating objects in the
scene.
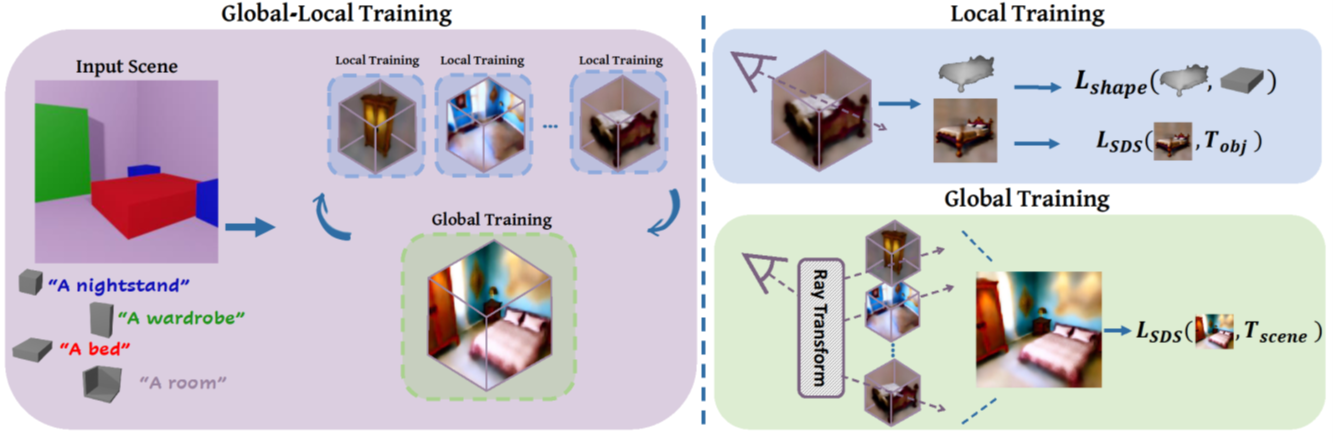
To remedy this deficit, we propose a novel Global-Local training framework for synthesizing a 3D
scene using object proxies. A proxy represents the object's placement in the generated scene and
optionally defines its coarse geometry.
The key to our approach is to represent each object as an independent NeRF. We alternate between
optimizing each NeRF on its own and as part of the full scene. Thus, a complete representation
of each object can be learned, while also creating a harmonious scene with style and lighting
match.
We show that using proxies allows a wide variety of editing options, such as adjusting the
placement of each independent object, removing objects from a scene, or refining an object.
Our results show that Set-the-Scene offers a powerful solution for scene synthesis and
manipulation, filling a crucial gap in controllable text-to-3D synthesis.